The conventional advice for AI retrieval is to pick a side.
You pick a vector database if you want similarity. You pick a graph
database if you want structure. You bolt them together with glue code
when the product inevitably needs both.
That framing has never matched the workloads I actually care about. The
interesting systems — agent memory, recommendations, internal search
over connected product data, knowledge graphs that feed chat features —
do not want a vector store or a graph store. They want to retrieve
candidates by similarity, then explain and filter those candidates by
relationships. Splitting that into two products splits the query path,
the data model, and eventually the team.
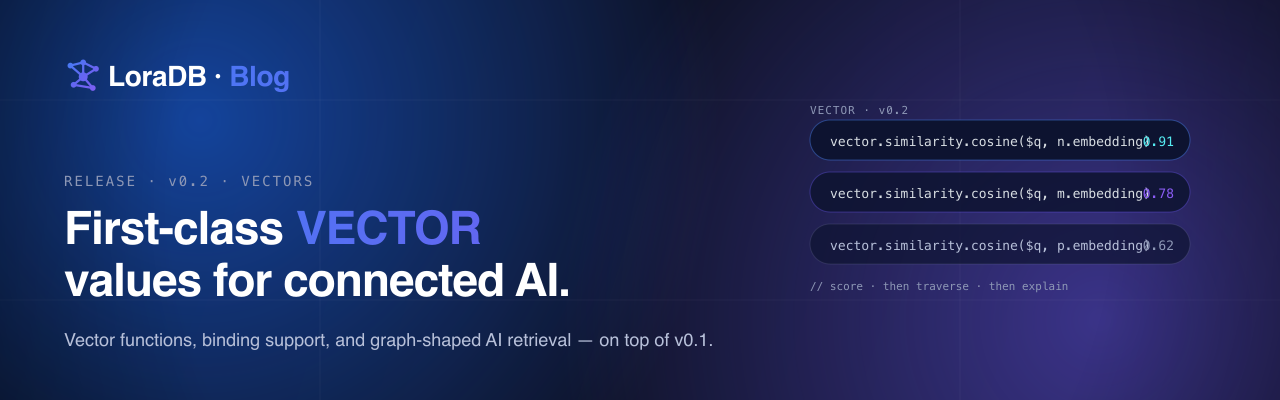
LoraDB v0.2 adds VECTOR as a first-class
value type. Vectors live directly on nodes and relationships, next to
labels, properties, and edges. The argument is not that a graph
database should replace a vector database. The argument is that
similarity belongs next to the relationships that give it meaning.