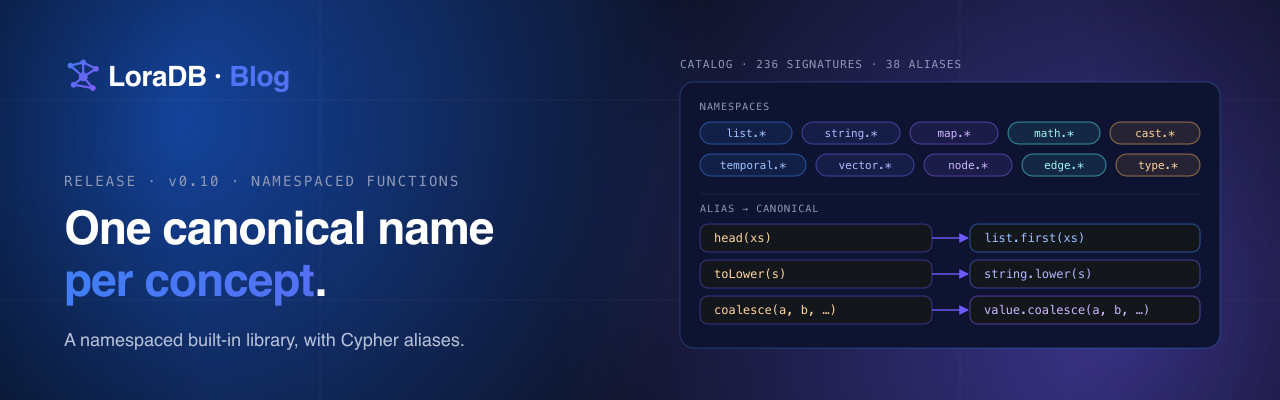
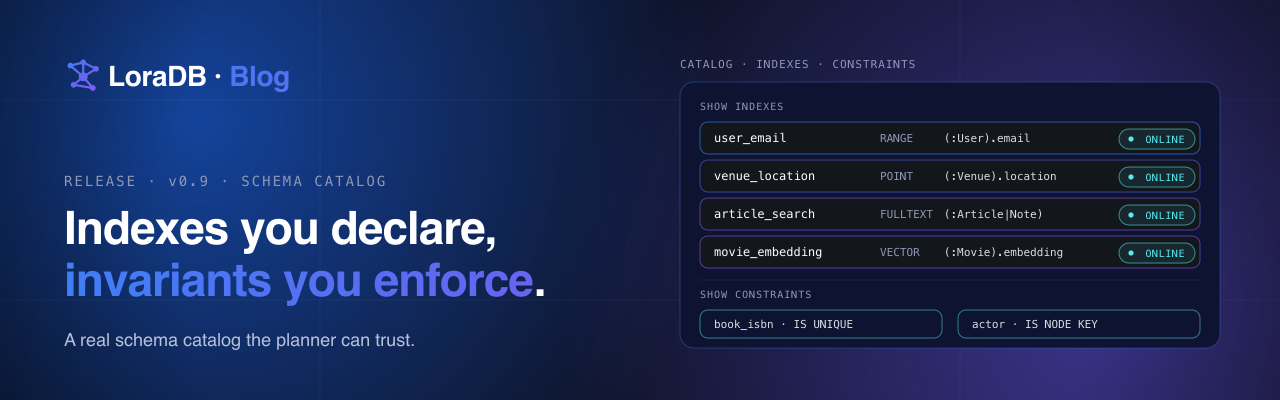
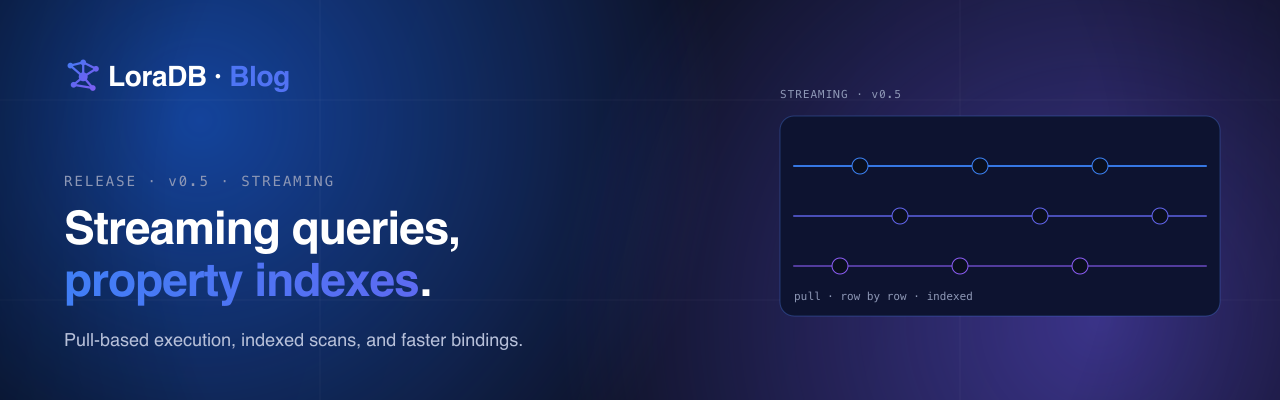
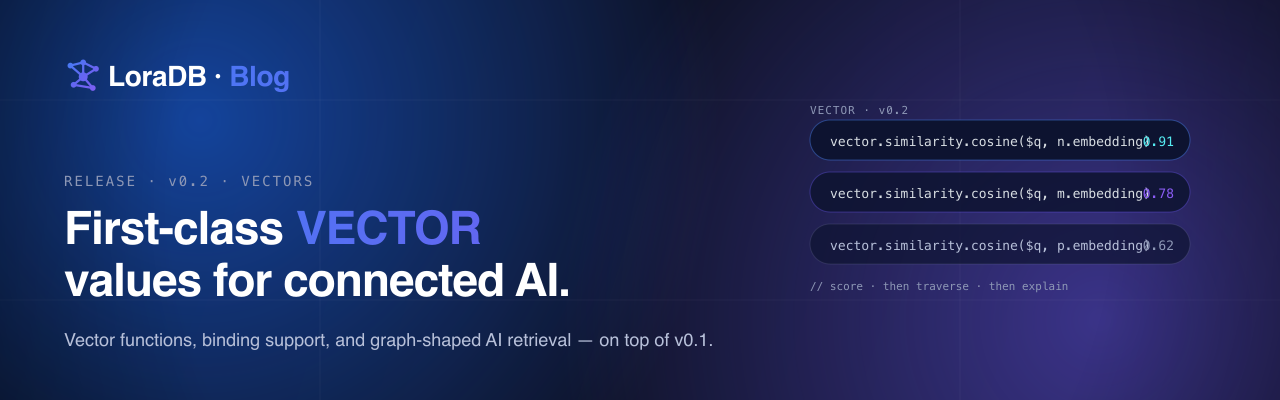
Where SQL quietly degrades

I do not want to write a post about how SQL is bad. SQL is not bad. Postgres is one of the most well-engineered pieces of software on the planet, and the relational model has held up for fifty years for very good reasons.
But the workloads I see developers actually building today are not the
workloads SQL was tuned for. And in almost every one of those
workloads, relational performance degrades. Not because of one
catastrophic failure, but because of a stack of small frictions that
compound into something you eventually start working around with
caches, read replicas, materialized views, and a Slack channel called
#schema-discussion.
This post is about where that degradation happens, and why it is structural rather than fixable with another index.