LoraDB v0.10: one canonical name per concept
· 10 min read

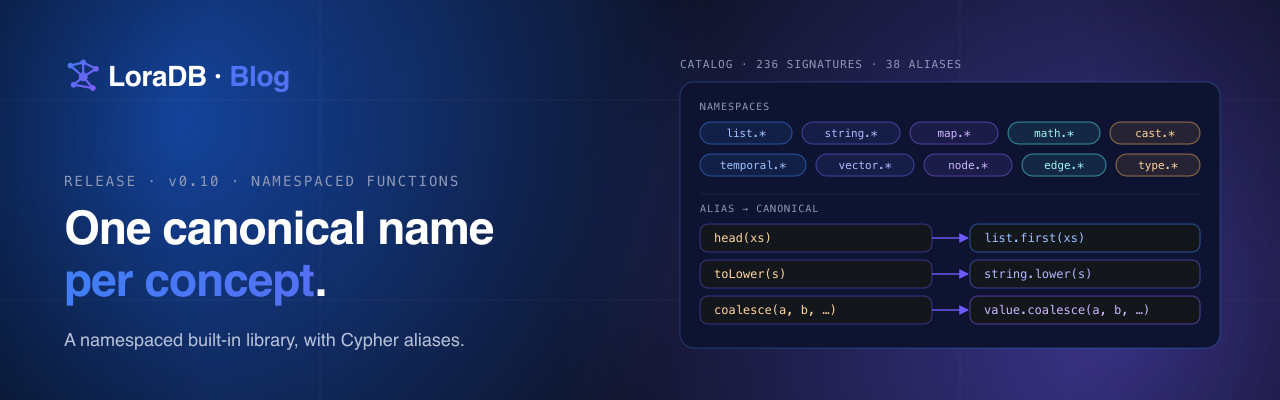
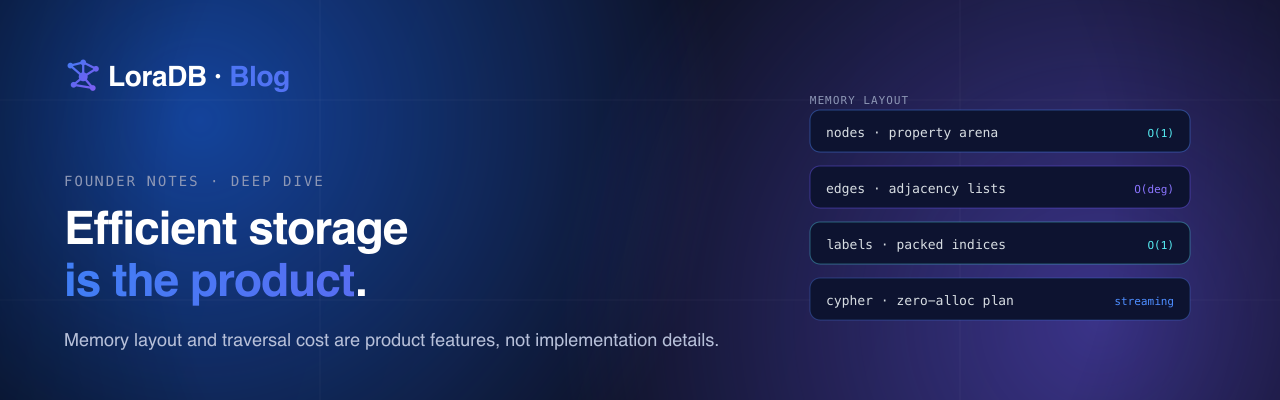
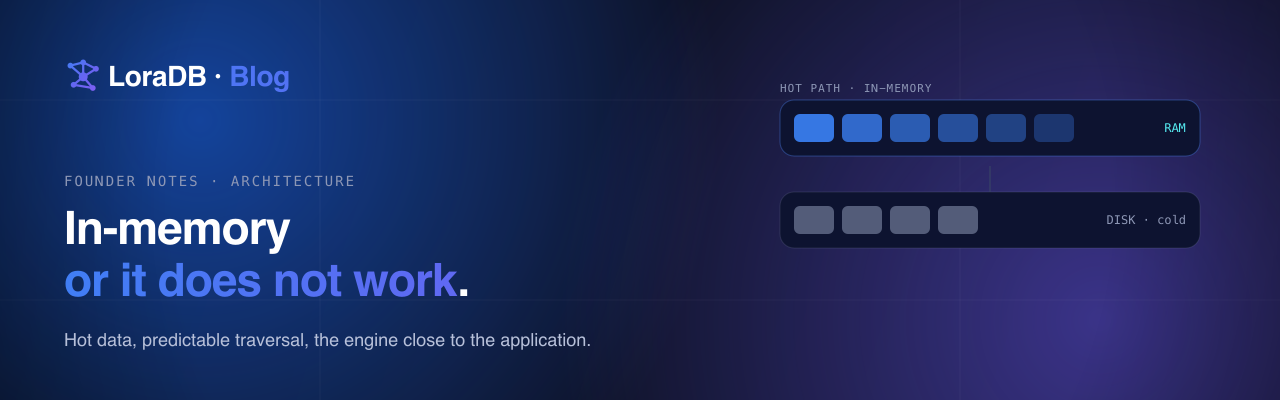
LoraDB v0.10 is a function-surface release.
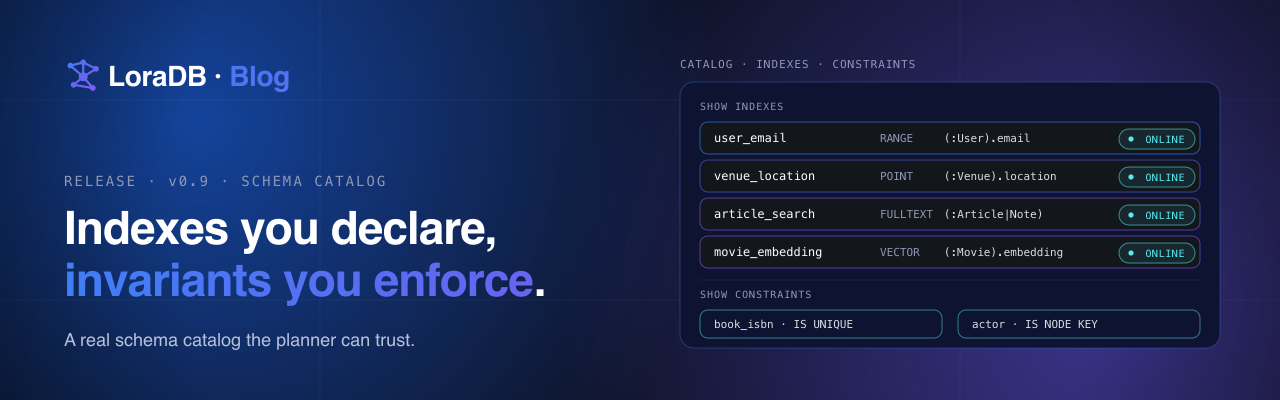
v0.5 made the engine stream. v0.6 made persistence feel like a system. v0.7 was a process release. v0.8 made the planner and executor observable. v0.9 gave the planner a real schema catalog.
v0.10 does the same thing for the function library: the engine now has one canonical name per concept, grouped into namespaces, with the analyzer, executor, optimizer, docs, and binding tests all reading from the same table.